diff --git a/README.md b/README.md
index 9d163f4..d0ea40a 100644
--- a/README.md
+++ b/README.md
@@ -67,10 +67,6 @@ result = DeepFace.verify(img1_path = "img1.jpg", img2_path = "img2.jpg")

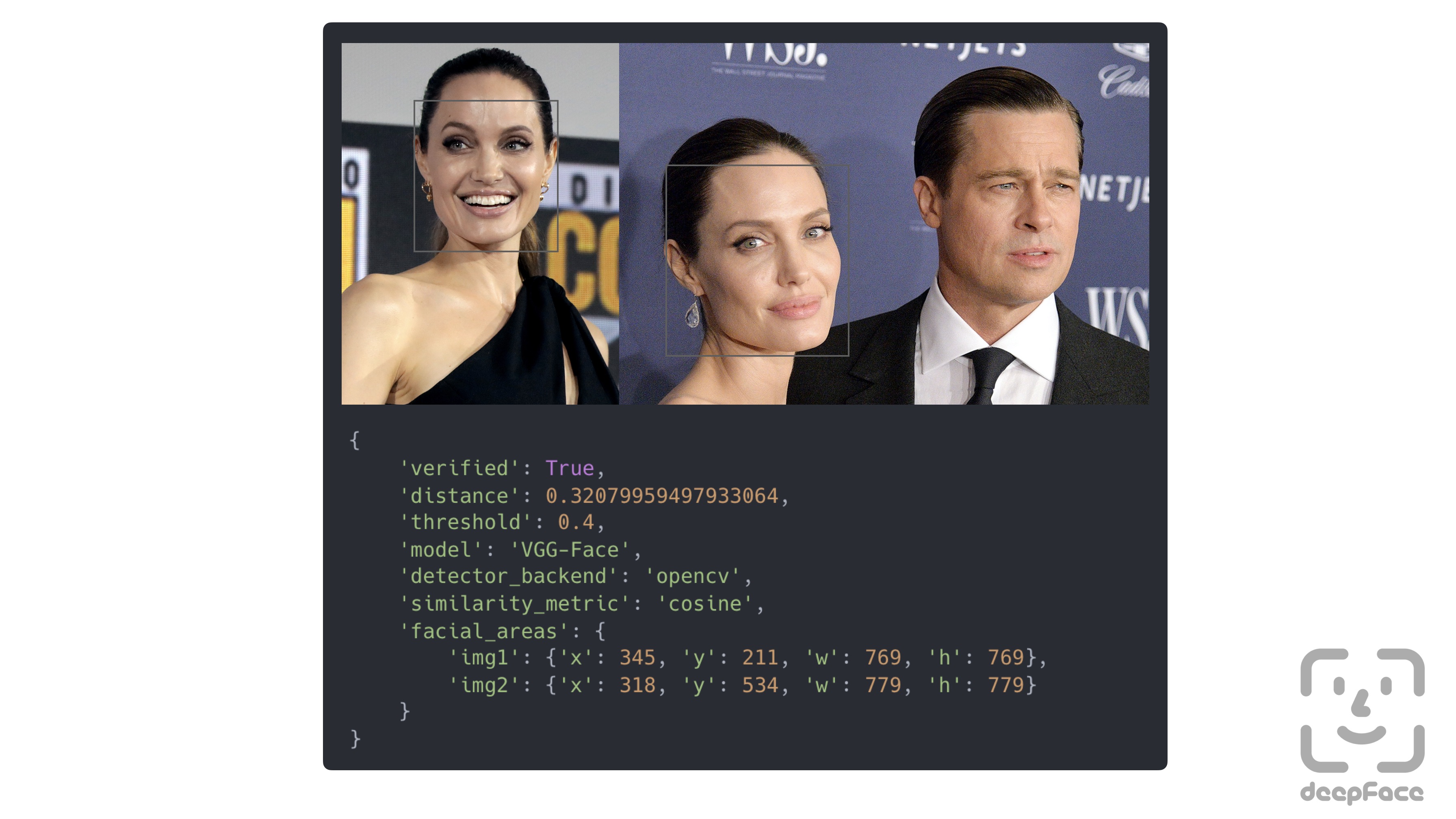
-Verification function can also handle many faces in the face pairs. In this case, the most similar faces will be compared.
-
-
-
**Face recognition** - [`Demo`](https://youtu.be/Hrjp-EStM_s)
[Face recognition](https://sefiks.com/2020/05/25/large-scale-face-recognition-for-deep-learning/) requires applying face verification many times. Herein, deepface has an out-of-the-box find function to handle this action. It's going to look for the identity of input image in the database path and it will return list of pandas data frame as output. Meanwhile, facial embeddings of the facial database are stored in a pickle file to be searched faster in next time. Result is going to be the size of faces appearing in the source image. Besides, target images in the database can have many faces as well.
@@ -244,7 +240,7 @@ face_objs = DeepFace.extract_faces(img_path = "img.jpg",
Face recognition models are actually CNN models and they expect standard sized inputs. So, resizing is required before representation. To avoid deformation, deepface adds black padding pixels according to the target size argument after detection and alignment.
-
+
[RetinaFace](https://sefiks.com/2021/04/27/deep-face-detection-with-retinaface-in-python/) and [MTCNN](https://sefiks.com/2020/09/09/deep-face-detection-with-mtcnn-in-python/) seem to overperform in detection and alignment stages but they are much slower. If the speed of your pipeline is more important, then you should use opencv or ssd. On the other hand, if you consider the accuracy, then you should use retinaface or mtcnn.
diff --git a/deepface/__init__.py b/deepface/__init__.py
index 0db49b7..a8d2e1f 100644
--- a/deepface/__init__.py
+++ b/deepface/__init__.py
@@ -1 +1 @@
-__version__ = "0.0.85"
+__version__ = "0.0.86"
diff --git a/deepface/detectors/FastMtCnn.py b/deepface/detectors/FastMtCnn.py
index f480643..88340c0 100644
--- a/deepface/detectors/FastMtCnn.py
+++ b/deepface/detectors/FastMtCnn.py
@@ -27,14 +27,21 @@ class FastMtCnnClient(Detector):
detections = self.model.detect(
img_rgb, landmarks=True
) # returns boundingbox, prob, landmark
- if detections is not None and len(detections) > 0:
-
+ if (
+ detections is not None
+ and len(detections) > 0
+ and not any(detection is None for detection in detections) # issue 1043
+ ):
for current_detection in zip(*detections):
x, y, w, h = xyxy_to_xywh(current_detection[0])
confidence = current_detection[1]
+
left_eye = current_detection[2][0]
right_eye = current_detection[2][1]
+ left_eye = tuple(int(i) for i in left_eye)
+ right_eye = tuple(int(i) for i in right_eye)
+
facial_area = FacialAreaRegion(
x=x,
y=y,
diff --git a/deepface/modules/preprocessing.py b/deepface/modules/preprocessing.py
index 4287dd0..42756c1 100644
--- a/deepface/modules/preprocessing.py
+++ b/deepface/modules/preprocessing.py
@@ -34,7 +34,7 @@ def load_image(img: Union[str, np.ndarray]) -> Tuple[np.ndarray, str]:
return load_base64(img), "base64 encoded string"
# The image is a url
- if img.startswith("http"):
+ if img.startswith("http://") or img.startswith("https://"):
return load_image_from_web(url=img), img
# The image is a path
@@ -76,7 +76,21 @@ def load_base64(uri: str) -> np.ndarray:
Returns:
numpy array: the loaded image.
"""
- encoded_data = uri.split(",")[1]
+
+ encoded_data_parts = uri.split(",")
+
+ if len(encoded_data_parts) < 2:
+ raise ValueError("format error in base64 encoded string")
+
+ # similar to find functionality, we are just considering these extensions
+ if not (
+ uri.startswith("data:image/jpeg")
+ or uri.startswith("data:image/jpg")
+ or uri.startswith("data:image/png")
+ ):
+ raise ValueError(f"input image can be jpg, jpeg or png, but it is {encoded_data_parts}")
+
+ encoded_data = encoded_data_parts[1]
nparr = np.fromstring(base64.b64decode(encoded_data), np.uint8)
img_bgr = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
diff --git a/deepface/modules/verification.py b/deepface/modules/verification.py
index b48d273..300c2f9 100644
--- a/deepface/modules/verification.py
+++ b/deepface/modules/verification.py
@@ -85,81 +85,84 @@ def verify(
model: FacialRecognition = modeling.build_model(model_name)
target_size = model.input_shape
- # img pairs might have many faces
- img1_objs = detection.extract_faces(
- img_path=img1_path,
- target_size=target_size,
- detector_backend=detector_backend,
- grayscale=False,
- enforce_detection=enforce_detection,
- align=align,
- expand_percentage=expand_percentage,
- )
+ try:
+ img1_objs = detection.extract_faces(
+ img_path=img1_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ expand_percentage=expand_percentage,
+ )
+ except ValueError as err:
+ raise ValueError("Exception while processing img1_path") from err
+
+ try:
+ img2_objs = detection.extract_faces(
+ img_path=img2_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ expand_percentage=expand_percentage,
+ )
+ except ValueError as err:
+ raise ValueError("Exception while processing img2_path") from err
+
+ img1_embeddings = []
+ for img1_obj in img1_objs:
+ img1_embedding_obj = representation.represent(
+ img_path=img1_obj["face"],
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+ img1_embedding = img1_embedding_obj[0]["embedding"]
+ img1_embeddings.append(img1_embedding)
+
+ img2_embeddings = []
+ for img2_obj in img2_objs:
+ img2_embedding_obj = representation.represent(
+ img_path=img2_obj["face"],
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+ img2_embedding = img2_embedding_obj[0]["embedding"]
+ img2_embeddings.append(img2_embedding)
- img2_objs = detection.extract_faces(
- img_path=img2_path,
- target_size=target_size,
- detector_backend=detector_backend,
- grayscale=False,
- enforce_detection=enforce_detection,
- align=align,
- expand_percentage=expand_percentage,
- )
- # --------------------------------
distances = []
regions = []
- # now we will find the face pair with minimum distance
- for img1_obj in img1_objs:
- img1_content = img1_obj["face"]
- img1_region = img1_obj["facial_area"]
- for img2_obj in img2_objs:
- img2_content = img2_obj["face"]
- img2_region = img2_obj["facial_area"]
- img1_embedding_obj = representation.represent(
- img_path=img1_content,
- model_name=model_name,
- enforce_detection=enforce_detection,
- detector_backend="skip",
- align=align,
- normalization=normalization,
- )
-
- img2_embedding_obj = representation.represent(
- img_path=img2_content,
- model_name=model_name,
- enforce_detection=enforce_detection,
- detector_backend="skip",
- align=align,
- normalization=normalization,
- )
-
- img1_representation = img1_embedding_obj[0]["embedding"]
- img2_representation = img2_embedding_obj[0]["embedding"]
-
+ for idx, img1_embedding in enumerate(img1_embeddings):
+ for idy, img2_embedding in enumerate(img2_embeddings):
if distance_metric == "cosine":
- distance = find_cosine_distance(img1_representation, img2_representation)
+ distance = find_cosine_distance(img1_embedding, img2_embedding)
elif distance_metric == "euclidean":
- distance = find_euclidean_distance(img1_representation, img2_representation)
+ distance = find_euclidean_distance(img1_embedding, img2_embedding)
elif distance_metric == "euclidean_l2":
distance = find_euclidean_distance(
- l2_normalize(img1_representation), l2_normalize(img2_representation)
+ l2_normalize(img1_embedding), l2_normalize(img2_embedding)
)
else:
raise ValueError("Invalid distance_metric passed - ", distance_metric)
-
distances.append(distance)
- regions.append((img1_region, img2_region))
+ regions.append((img1_objs[idx]["facial_area"], img2_objs[idy]["facial_area"]))
- # -------------------------------
+ # find the face pair with minimum distance
threshold = find_threshold(model_name, distance_metric)
- distance = min(distances) # best distance
+ distance = float(min(distances)) # best distance
facial_areas = regions[np.argmin(distances)]
toc = time.time()
- # pylint: disable=simplifiable-if-expression
resp_obj = {
- "verified": True if distance <= threshold else False,
+ "verified": distance <= threshold,
"distance": distance,
"threshold": threshold,
"model": model_name,
diff --git a/icon/detector-outputs-20240302.jpg b/icon/detector-outputs-20240302.jpg
new file mode 100644
index 0000000..b7bf517
Binary files /dev/null and b/icon/detector-outputs-20240302.jpg differ
diff --git a/package_info.json b/package_info.json
index 6f4bc61..1166070 100644
--- a/package_info.json
+++ b/package_info.json
@@ -1,3 +1,3 @@
{
- "version": "0.0.85"
+ "version": "0.0.86"
}
\ No newline at end of file
diff --git a/tests/test_enforce_detection.py b/tests/test_enforce_detection.py
index 74c4704..9c90ea9 100644
--- a/tests/test_enforce_detection.py
+++ b/tests/test_enforce_detection.py
@@ -9,10 +9,10 @@ logger = Logger("tests/test_enforce_detection.py")
def test_enabled_enforce_detection_for_non_facial_input():
black_img = np.zeros([224, 224, 3])
- with pytest.raises(ValueError, match="Face could not be detected."):
+ with pytest.raises(ValueError):
DeepFace.represent(img_path=black_img)
- with pytest.raises(ValueError, match="Face could not be detected."):
+ with pytest.raises(ValueError):
DeepFace.verify(img1_path=black_img, img2_path=black_img)
logger.info("✅ enabled enforce detection with non facial input tests done")
diff --git a/tests/visual-test.py b/tests/visual-test.py
index 239c3bc..99d0a3f 100644
--- a/tests/visual-test.py
+++ b/tests/visual-test.py
@@ -25,6 +25,7 @@ detector_backends = [
"ssd",
"dlib",
"mtcnn",
+ "fastmtcnn",
# "mediapipe", # crashed in mac
"retinaface",
"yunet",
@@ -56,40 +57,39 @@ for df in dfs:
logger.info(df)
+expand_areas = [0, 25]
+img_paths = ["dataset/img11.jpg", "dataset/img11_reflection.jpg"]
+for expand_area in expand_areas:
+ for img_path in img_paths:
+ # extract faces
+ for detector_backend in detector_backends:
+ face_objs = DeepFace.extract_faces(
+ img_path=img_path,
+ detector_backend=detector_backend,
+ align=True,
+ expand_percentage=expand_area,
+ )
+ for face_obj in face_objs:
+ face = face_obj["face"]
+ logger.info(detector_backend)
+ logger.info(face_obj["facial_area"])
+ logger.info(face_obj["confidence"])
-# img_paths = ["dataset/img11.jpg", "dataset/img11_reflection.jpg", "dataset/couple.jpg"]
-img_paths = ["dataset/img11.jpg"]
-for img_path in img_paths:
- # extract faces
- for detector_backend in detector_backends:
- face_objs = DeepFace.extract_faces(
- img_path=img_path,
- detector_backend=detector_backend,
- align=True,
- # expand_percentage=10,
- # target_size=None,
- )
- for face_obj in face_objs:
- face = face_obj["face"]
- logger.info(detector_backend)
- logger.info(face_obj["facial_area"])
- logger.info(face_obj["confidence"])
+ # we know opencv sometimes cannot find eyes
+ if face_obj["facial_area"]["left_eye"] is not None:
+ assert isinstance(face_obj["facial_area"]["left_eye"], tuple)
+ assert isinstance(face_obj["facial_area"]["left_eye"][0], int)
+ assert isinstance(face_obj["facial_area"]["left_eye"][1], int)
- # we know opencv sometimes cannot find eyes
- if face_obj["facial_area"]["left_eye"] is not None:
- assert isinstance(face_obj["facial_area"]["left_eye"], tuple)
- assert isinstance(face_obj["facial_area"]["left_eye"][0], int)
- assert isinstance(face_obj["facial_area"]["left_eye"][1], int)
+ if face_obj["facial_area"]["right_eye"] is not None:
+ assert isinstance(face_obj["facial_area"]["right_eye"], tuple)
+ assert isinstance(face_obj["facial_area"]["right_eye"][0], int)
+ assert isinstance(face_obj["facial_area"]["right_eye"][1], int)
- if face_obj["facial_area"]["right_eye"] is not None:
- assert isinstance(face_obj["facial_area"]["right_eye"], tuple)
- assert isinstance(face_obj["facial_area"]["right_eye"][0], int)
- assert isinstance(face_obj["facial_area"]["right_eye"][1], int)
+ assert isinstance(face_obj["confidence"], float)
+ assert face_obj["confidence"] <= 1
- assert isinstance(face_obj["confidence"], float)
- assert face_obj["confidence"] <= 1
-
- plt.imshow(face)
- plt.axis("off")
- plt.show()
- logger.info("-----------")
+ plt.imshow(face)
+ plt.axis("off")
+ plt.show()
+ logger.info("-----------")